LearningWebRTC: 音频重采样
WebRTC的音频模块中,不同模块的衔接,存在大量重采样, 如Decoder和AudioMixer,AudioMixer和AudioDvice等。
这篇文章深入介绍重采样的原理,以及WebRTC的两个实现类。 其中,理解理想重采样是关键。
标记:
- 输入数字信号x[i], 0<=i<=I
- 重采样输出数字信号y[j], 0<=j<=J.
- N/M重采样,表示重采样的输入输出样本数的比例,N,M为互质数。N/M=I/J.
- F: 重采样滤波器阶数。
- C: 声道数。
理想重采样
原理
数字信号由模拟信号采样而来,如果满足”采样定理”,那么,数字信号就可以完全恢复原始的模拟信号。 恢复的方式如下图:
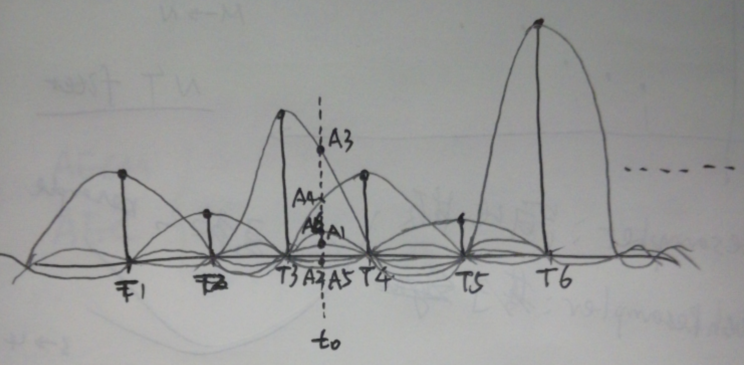
理想的重采样,相当于是在恢复的模拟信号上,以新的采样率重新采样得到数字信号y[j]。 如上图中的采样点t0,采样结果为: y[t0] = A1+A2+A3+…。 其中Ak,表示原数字信号x[k]经过sinc函数滤波后在t0点的值。
sinc函数定义为:
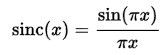 重采样滤波器系数,就是sinc函数上的采样点。
重采样滤波器系数,就是sinc函数上的采样点。
对理想重采样而言,y[j]上任一点,都需要x[i]上所有点滤波得到,原因是sinc函数是一个时域无限长的信号。
时间复杂度
- 每一个输出点,都需要做一次长度为I的滤波,因此需要I*J次乘法。
空间复杂度:
- 滤波器个数: M
- 滤波器系数: 假设滤波器阶数为F,对理想重采样,F=I,也就是需要M*F个滤波器系数。
- 滤波器历史状态: 每个滤波器需要存储F-1个状态,总共M * (F-1) * C个。
- 总内存(假设以double存储): 4 * (M * F + M * (F-1) * C ) 字节.
延迟
- 需要等到输入信号x[i]全部到达才能得到y[0], 因此延迟为I个样本点。
WebRTC PushResampler
PushResampler是WebRTC中最精确,也是时间复杂度最大的重采样类,同时又对理想重采样算法做了一定的简化。
原理
- 简化一: 滤波器阶数F, 默认只有32阶。
- 简化二: 固定滤波器的种数,即x[i]~x[i+1]间的subsample数,为32个。对于N/M重采样中,如果M!=32,则找到重采样点j在哪两个subsample之间,然后用线性内插的方式得到y[j].
- 理想重采样中,当M特别大时,内存耗费就会特别大,我曾经优化过960/1001的重采样,共有15个声道,如果滤波器为32阶,那总共需要内存约1.86MB!
时间复杂度
- 每个y[j]需要两个阶数为32的滤波器内插得到,一共J个输出样本点,因此需要乘法次数: J * (2 * F + 2)
空间复杂度:
- 需要保存32种滤波器系数
- 每个声道需要保存2*(F-1)个滤波器状态
- 总共: 4 * (32 + C * 2 * (F-1))字节。
延迟
- F/2 = 16个样本点。
WebRTC Resampler
对于某些特殊的重采样比率,可以进一步减少复杂度,这就是Resampler类。 Resampler支持下面比例的重采样:
enum ResamplerMode {
kResamplerMode1To1,
kResamplerMode1To2,
kResamplerMode1To3,
kResamplerMode1To4,
kResamplerMode1To6,
kResamplerMode1To12,
kResamplerMode2To3,
kResamplerMode2To11,
kResamplerMode4To11,
kResamplerMode8To11,
kResamplerMode11To16,
kResamplerMode11To32,
kResamplerMode2To1,
kResamplerMode3To1,
kResamplerMode4To1,
kResamplerMode6To1,
kResamplerMode12To1,
kResamplerMode3To2,
kResamplerMode11To2,
kResamplerMode11To4,
kResamplerMode11To8
};
其中kResamplerMode4To11, 相当于8khz上采样到22khz,被拆分成三个stage,8khz->16khz->11khz->22khz. 另外kResamplerMode8To11, 相当于16khz上采样到22khz,被拆分成两个stage,16khz->32khz->22khz.因此,与kResamplerMode4To11前两个stage可以复用。
参考
- WebRTC M59源码
xjs.xjtu@gmail.com
2017-07-08